SQLPassthroughDataSets
Use multiple queries in a single SQLPassthroughDataSet where it makes sense
The SQLPassthroughDataSet format supports multiple queries within a single SQLPassthroughDataSet specification and, as such, multiple queries may be executed on a single trip from the Dodeca client to the Dodeca server. Due to the design of the SQLPassthroughDataSet object, each query, or DataTable using DataSet terminology, has a separate SQLConnection associated with it. This means that a single SQLPassthroughDataSet object has the ability to call different data sources, and even different database products such as Oracle Database and Microsoft SQL Server, in a single call to the server.
When there are multiple queries, use the ConcurrentQueryExecutionEnabled property to run all queries simultaneously
The SQLPassthroughDataSet object contains the ConcurrentQueryExecutionEnabled property which, when set to True, launches a separate thread on the server for each specified query, executes the queries in parallel, waits until the last query completes, and then returns the results of all queries as separate DataTable objects within the DataSet object using standard Microsoft DataSet xml formats.
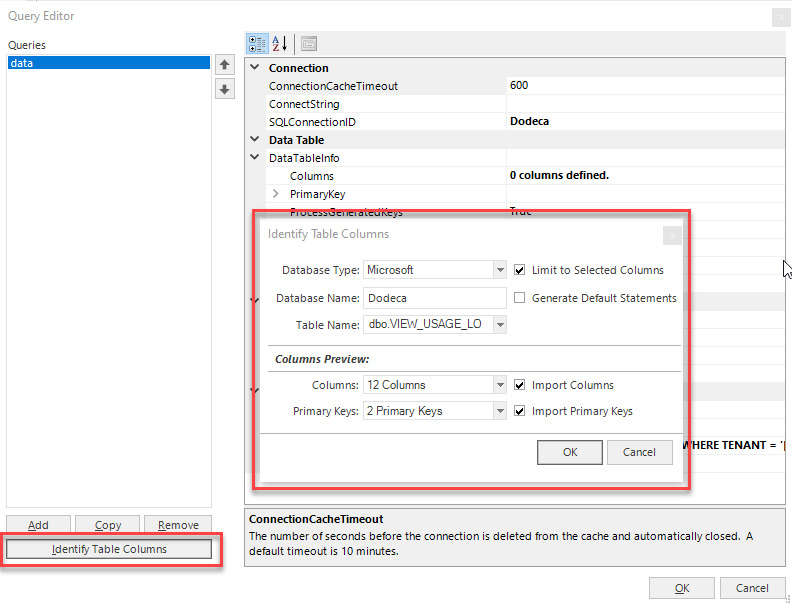
Use the Identify Table Columns button to fill column definitions
Due to differences in JDBC driver capabilities to identify column types in a Java resultset, the Dodeca SQL Query configuration includes a table where column names and types can be defined. These definitions are particularly important during update and insert operations as the internal Java code to set the value of a column is different for different data types.
In early versions of Dodeca, this mapping was done manually. Starting in Dodeca 7.6, a new button was added to the Dodeca Query Editor form that will read the type of database and read system tables to obtain and fill column names and types into the Query object.
Use the IncrementalMaxRows to return large data sets in chunks to reduce server memory usage
SQLPassthroughDataSet objects, by default, return all records returned by the query in one xml response. In some cases, however, the number of records can be quite large and significant amounts of memory can be consumed on the server which could lead to OutOfMemory issues on the server. This potential is multiplied when numerous users are simultaneously making large queries. The amount of memory consumed can be limited by setting the IncrementalMaxRows property to an appropriate value.
The IncrementalMaxRows property cuts the response into multiple parts which are sent back to the client. The client then assembles the parts into a DataSet containing all of the records before it is consumed on the client. For example, if a query returns 50,000 rows and the IncrementalMaxRows property is set to 10,000 rows, the client will call the server 5 times to get each incremental number of rows.
The value of the IncrementalMaxRows to use for best performance is judgmental and is based on the amount of server memory and the size of each row. It is best to make an estimate the IncrementalMaxRows to start and to use trial and error to find the best performance.
Use the FetchSize to tune large data retrievals
The JDBC FetchSize property is used to tune data retrievals in order to balance memory usage and performance. Depending on the JDBC driver, the default FetchSize could be small optimizing memory usage at the expense of making more network calls to the server, or the default FetchSize could be large reducing the number of network calls to the server at the cost of more memory usage.